UNMASKING DEEPFAKES: MASKED AUTOENCODING SPATIOTEMPORAL TRANSFORMERS FOR ENHANCED VIDEO FORGERY DETECTION
Published in IJCB, 2023
Abstract
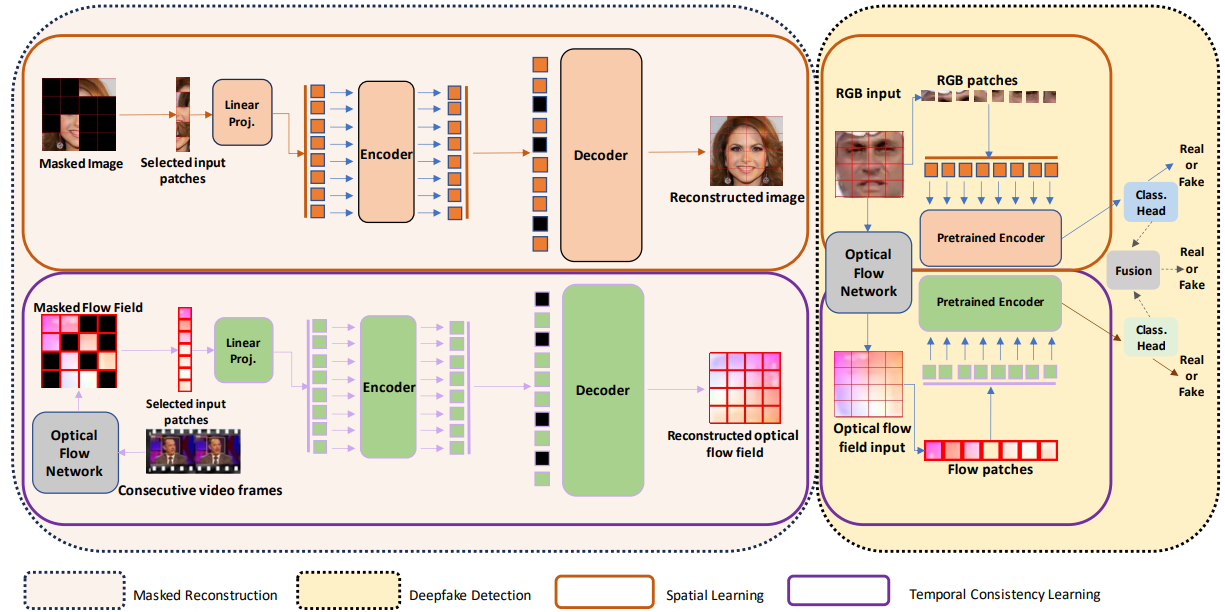
We present a novel approach for the detection of deepfake videos using a pair of vision transformers pre-trained by a self-supervised masked autoencoding setup. Our method consists of two distinct components, one of which focuses on learning spatial information from individual RGB frames of the video, while the other learns temporal consistency information from optical flow fields generated from consecutive frames. Unlike most approaches where pre-training is performed on a generic large corpus of images, we show that by pre-training on smaller face-related datasets, namely Celeb-A (for the spatial learning component) and YouTube Faces (for the temporal learning component), strong results can be obtained. We perform various experiments to evaluate the performance of our method on commonly used datasets namely FaceForensics++ (Low Quality and High Quality, along with a new highly compressed version named Very Low Quality) and Celeb-DFv2 datasets. Our experiments show that our method sets a new state-of-the-art on FaceForensics++ (LQ, HQ, and VLQ), and obtains competitive results on Celeb-DFv2. Moreover, our method outperforms other methods in the area in a cross-dataset setup where we fine-tune our model on FaceForensics++ and test on CelebDFv2, pointing to its strong cross-dataset generalization ability.
Recommended citation:
@article{das2023unmasking,
title = {Unmasking Deepfakes: Masked Autoencoding Spatiotemporal Transformers for Enhanced Video Forgery Detection},
author = {Sayantan Das and Mojtaba Kolahdouzi and Levent Özparlak and Will Hickie and Ali Etemad},
year = {2023},
journal = {International Joint Conference on Biometrics}
}